计算机视觉领域的前沿发展
引言
计算机视觉(CV)作为人工智能的重要分支,致力于让机器理解和解析图像与视频。其应用广泛,从自动驾驶到医疗影像分析,各行各业都在积极探索这一技术,以提升效率和准确性。
深度学习推动CV进步
深度学习模型,特别是卷积神经网络(CNN),极大地推动了计算机视觉的发展。这些模型通过模仿人类处理图像的方式,使得物体识别、面部识别等任务变得更加高效。在众多数据集上进行训练后,这些算法能够以超乎寻常的精确度进行预测👍。
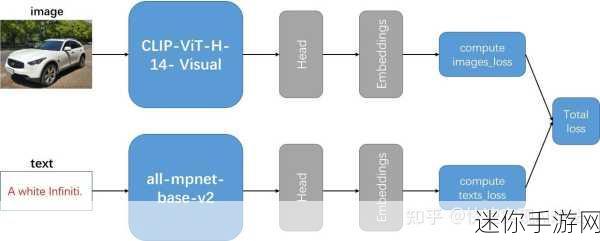
数据标注和扩增方法
为了提高模型性能,大规模的数据标注成为必不可少的一环。同时,通过数据增强技巧如旋转、缩放及颜色调整,可以有效增加训练样本数量,使得模型具备更好的鲁棒性📈。
模型架构演化
近年来,不同类型的网络结构层出不穷。从最初的AlexNet,到VGG,再到ResNet,每一代新颖架构不仅仅在参数量上进行了优化,更是在特征提取能力上取得了显著突破🔍。这些进展使得复杂场景下的目标检测变为可能🌟。
Transformer在CV中的应用
Transformers已被成功引入计算机视觉领域,其自注意力机制可以捕捉全局上下文关系,有助于解决传统CNN难以克服的问题🎨。Vision Transformers (ViTs) 在多个基准测试中表现优异,为研究提供了新的方向✨。
应用案例探讨
具体来说,医学影像分析利用 CV 技术实现早期疾病诊断。例如,通过对CT扫描图像进行分析,可以帮助医生快速发现潜在肿瘤🏥。此外,人脸识别系统也日益成熟,在安全监控、金融交易认证等方面得到广泛运用💳。
自动驾驶与交通管理
无论是实时路况监测还是行车环境感知,对于自动驾驶汽车而言,高质量的视频输入尤为重要🚗。结合雷达信息以及摄像头捕获的数据,可实现精准判断,提高道路安全系数✅。
持续挑战与未来趋势
尽管已经取得诸多成就,但仍存在不少挑战。如如何减少偏见、防止过拟合,以及面对不同光照条件或遮挡情况时保持稳定性🤔。此外,还需考虑隐私问题,如个人肖像权保护👀,这将促使行业规范不断完善⚖️♂️。
多模态融合发展的必要性
未来,多种传感器数据融合(例如结合音频、文本及视频)有望显著提升理解效果🛠️。这推向了一种“全面视角”,能更好地反映真实世界情况🔥。而且随着算力水平提升,各类轻量级模型将在移动设备端获得良好的执行效果📱.
技术伦理问题讨论
随着AI技术迅速发展,相应法律法规尚未完全跟上。这意味着需要更多关注道德责任,例如如何保证开发者使用公正透明的方法来创建算法,并确保用户权益受到尊重⚡️。同时,加强公众教育,让普通用户了解相关风险,也至关重要✏️🍃 。
问答部分
什么是卷积神经网络,它为何如此重要?
- 卷积神经网络是一种专门用于处理格状结构数据(如图像)的深度学习框架,它通过卷积操作有效提取特征,并降低参数数量,从而提升效率和准确率。
Vision Transformers 与 CNN 有何不同之处?
- Vision Transformers 使用自注意机制来建模长距离依赖关系,而 CNN 则主要依靠局部连接及池化层逐步提取特征,两者各有优势,根据具体任务选择适当方案即可。
参考文献
- "Deep Learning for Computer Vision"
- "The Rise of Visual Transformers"







